Bom.Squad
0.0.0
See the version list below for details.
dotnet add package Bom.Squad --version 0.0.0
NuGet\Install-Package Bom.Squad -Version 0.0.0
<PackageReference Include="Bom.Squad" Version="0.0.0" />
paket add Bom.Squad --version 0.0.0
#r "nuget: Bom.Squad, 0.0.0"
// Install Bom.Squad as a Cake Addin
#addin nuget:?package=Bom.Squad&version=0.0.0
// Install Bom.Squad as a Cake Tool
#tool nuget:?package=Bom.Squad&version=0.0.0
💣 Bom.Squad




Quick Start
dotnet add package Bom.Squad
using Bom.Squad;
BomSquad.DefuseUtf8Bom();
Problem
When serializing Unicode strings into bytes, there are several different strategies to choose from.
UTF-16 is one such format, and it tranforms each codepoint (character) into two or four bytes. Since there are multiple bytes for each codepoint, it is important for the deserializer to determine the order of those bytes, as they can start with the most significant byte (big endian network byte order) or the least significant byte (little endian CPU byte order). To detect the serialized byte order, UTF-16 deserializers look for a well-known prefix of two bytes and uses its value to determine the endianness (0xFEFF indicates UTF-16 BE, and 0xFFFE indicates UTF-16 LE). This prefix is the byte order marker (BOM).
UTF-8 is another Unicode transformation format, and each codepoint can be serialized by one to four bytes. However, unlike UTF-16, bytes in UTF-8 only have one ordering. It is invalid to shuffle the order of UTF-8 bytes. Therefore, UTF-8 does not need a byte order marker, as there is only one possible byte order. It is valid to include a BOM anyway (0xEFBBBF), but it doesn't mark a byte order, it only indicates that the bytes represent UTF-8 code units, as opposed to those of UTF-16 or ASCII or other encoding formats.
Unfortunately, Microsoft has decided that UTF-8 bytes should always be prefixed with the UTF-8 BOM. Most Microsoft products like .NET and PowerShell will prefix UTF-8 streams with a BOM. This is a very serious interoperability problem because most UTF-8 decoders (excluding those made by Microsoft) do not decode or interpret the BOM prefix, which results in 3 malformed bytes appearing at the beginning of all decoded strings instead of being stripped out by the decoder as intended. Furthermore, these bytes map to unprintable glyphs, so a visual inspection of the decoded string will not reveal the reason the string has malformed data at the beginning, unless it occurs to you to open it in a hex editor. Any further processing of this malformed data, such as pattern matching, parsing, or concatenating with other strings, will result in data corruption and incorrect results.
Examples of software that have encountered confusing, time-consuming errors because Microsoft encoded a BOM into UTF-8 data are
In conclusion, Microsoft's valid but highly-incompatible defaults result in corruption when data is shared between Microsoft and non-Microsoft software.
Solutions
Manually construct UTF8Encoding instances
The UTF-8 encoding functionality in .NET is contained in the System.Text.UTF8Encoding class. It takes a constructor parameter, encoderShouldEmitUTF8Identifier, that determines whether the encoder should output a BOM or not.
new UTF8Encoding(encoderShouldEmitUTF8Identifier: true, throwOnInvalidBytes: true); // output BOM
new UTF8Encoding(encoderShouldEmitUTF8Identifier: false, throwOnInvalidBytes: true); // don't output BOM
UTF-8 is most commonly specified in .NET using the static property Encoding.UTF8. This value is based on a UTF8Encoding instance that has encoderShouldEmitUTF8Identifier set to true, which is why it's so common for PowerShell and .NET programs to output BOMs when they encode strings to UTF-8.
The most straightfoward fix for this problem is to manually construct a UTF8Encoding instance with the desired constructor parameters any time you are able to pass an Encoding parameter to any method.
new StreamWriter(stream, new UTF8Encoding(false, true));
In previous versions of .NET runtimes, there was a defect where constructing a UTF8Encoding with encoderShouldEmitUTF8Identifier set to false would also prevent it from decoding a UTF-8 string that started with a BOM, which required you to create multiple UTF8Encoding instances with different constructor parameters, one for encoding and one for decoding. Thankfully, this has been fixed in more recent runtimes — verified in .NET Framework 4.5.2, 4.6.2, 4.7.2, 4.8, .NET 6, and .NET 7. Therefore, you can just create new UTF8Encoding(false, true) and store it as a public static field somewhere that you can access anywhere in your codebase.
Code inspection
If you're worried about forgetting to use new UTF8Encoding(false, true) instead of Encoding.UTF8, you can create a custom IDE inspection in ReSharper.
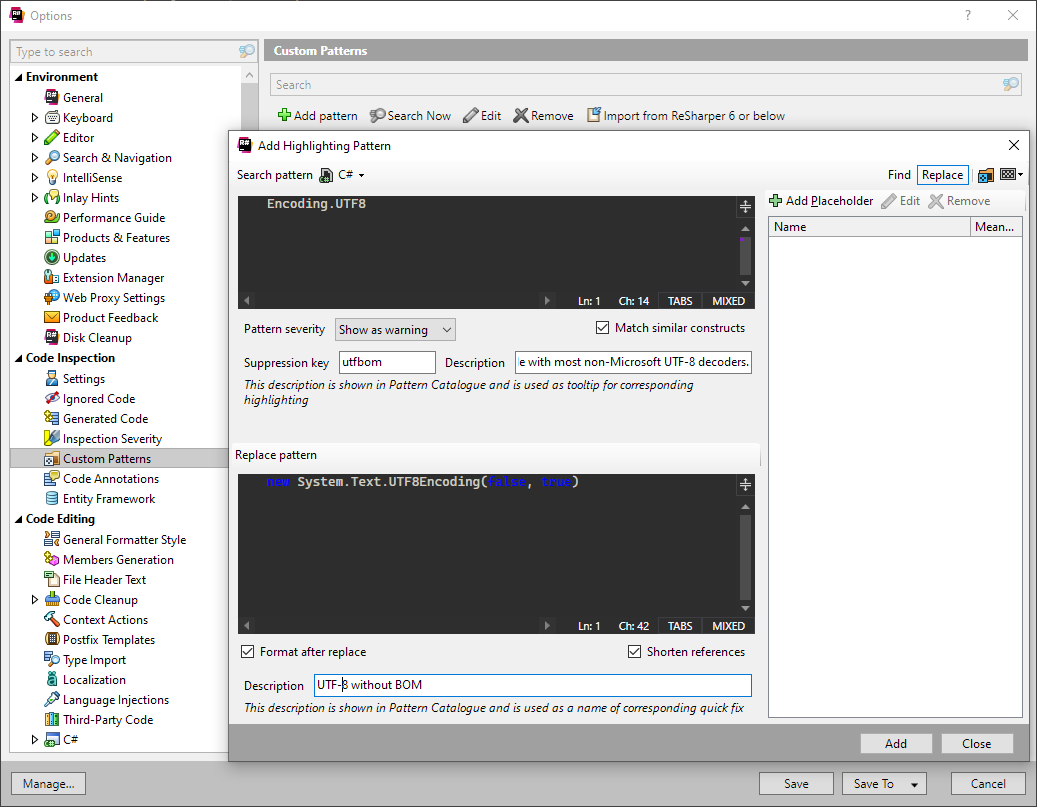
- Go to ReSharper → Options → Code Inspection → Custom Patterns → Add Pattern.
- Set Search pattern to
Encoding.UTF8. - Set Pattern severity to
Show as warningor whatever level you want. - Set Suppression key to something like
utfbomand its Description to something likeEncoding.UTF8 includes a BOM, which is incompatible with most non-Microsoft UTF-8 decoders.. - Set Replace pattern to
new System.Text.UTF8Encoding(false, true). - Enable Format after replace.
- Enable Shorten references.
- Set Dscription to something like
UTF8 without BOM. - Click Save.
Cross-cutting program-wide fix
Managing all of those custom instances of UTF8Encoder can be annoying and hard to keep track of. There may not be a good place to share one Encoding instance, and some code may not let you specify your own Encoding.
To fix this, you can disable UTF-8 BOM encoding for your entire program by replacing the Encoding.UTF8 method body with one that returns a UTF8Encoder instance that has encoderShouldEmitUTF8Identifier set to false. This functionality has been packed into the Bom.Squad NuGet package.
using Bom.Squad;
public class Program {
public static void Main(string[] args){
BomSquad.DefuseUtf8Bom();
// rest of your program
}
}
Subsequent calls to Encoding.UTF8 will return an instance with encoderShouldEmitUTF8Identifier set to false.
It is recommended to call this early in the execution of your program, such as at the top of your Main() method or in a WPF Application.OnStartup(StartupEventArgs) method. If you call Encoding.UTF8 immediately after calling DefuseUtf8Bom() in the same method, the changes may not take effect, so it's helpful to call DefuseUtf8Bom() earlier.
This approach uses spinico/MethodRedirect to replace the method body of the Encoding.UTF8 property getter at runtime.
| Product | Versions Compatible and additional computed target framework versions. |
|---|---|
| .NET | net5.0 was computed. net5.0-windows was computed. net6.0 was computed. net6.0-android was computed. net6.0-ios was computed. net6.0-maccatalyst was computed. net6.0-macos was computed. net6.0-tvos was computed. net6.0-windows was computed. net7.0 was computed. net7.0-android was computed. net7.0-ios was computed. net7.0-maccatalyst was computed. net7.0-macos was computed. net7.0-tvos was computed. net7.0-windows was computed. net8.0 was computed. net8.0-android was computed. net8.0-browser was computed. net8.0-ios was computed. net8.0-maccatalyst was computed. net8.0-macos was computed. net8.0-tvos was computed. net8.0-windows was computed. |
| .NET Core | netcoreapp2.0 was computed. netcoreapp2.1 was computed. netcoreapp2.2 was computed. netcoreapp3.0 was computed. netcoreapp3.1 was computed. |
| .NET Standard | netstandard2.0 is compatible. netstandard2.1 was computed. |
| .NET Framework | net452 is compatible. net46 was computed. net461 was computed. net462 was computed. net463 was computed. net47 was computed. net471 was computed. net472 was computed. net48 was computed. net481 was computed. |
| MonoAndroid | monoandroid was computed. |
| MonoMac | monomac was computed. |
| MonoTouch | monotouch was computed. |
| Tizen | tizen40 was computed. tizen60 was computed. |
| Xamarin.iOS | xamarinios was computed. |
| Xamarin.Mac | xamarinmac was computed. |
| Xamarin.TVOS | xamarintvos was computed. |
| Xamarin.WatchOS | xamarinwatchos was computed. |
-
.NETFramework 4.5.2
- No dependencies.
-
.NETStandard 2.0
- No dependencies.
NuGet packages
This package is not used by any NuGet packages.
GitHub repositories
This package is not used by any popular GitHub repositories.